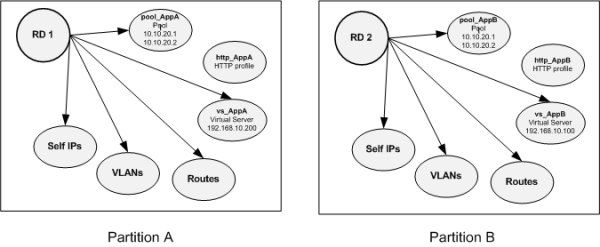
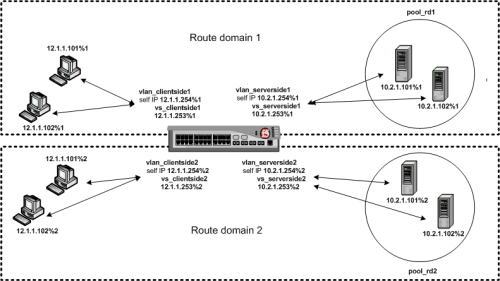
How virtual servers using the routes.
The BIG-IP system contains two sets of routing tables:
- The Linux routing tables, for routing administrative traffic through the management interface
- A special TMM routing table, for routing application and administrative traffic through the TMM interfaces
As a BIG-IP administrator, you can configure the system so that the BIG-IP system can use these routing tables to route both management and application traffic successfully.
Additional Information
When BIG-IP system using the routes it will select the most specific route to forward the traffic towards the destination.
About BIG-IP management routes and TMM routes:
Management routes
Management routes are routes that the BIG-IP system uses to forward traffic through the special management interface. The BIG-IP system stores management routes in the Linux (that is, kernel) routing table.
TMM routes
TMM routes are routes that the BIG-IP system uses to forward traffic through the Traffic Management Microkernel (TMM) interfaces instead of through the management interface. The BIG-IP system stores TMM routes in both the TMM and kernel routing tables.
As described, the BIG-IP routing table consists of a combination of routing subtables. A subtable for management routes, and a subtable for TMM routes. Routes in the TMM subtable are defined with a lower metric than routes in the management subtable. As a result, if an equally specific route exists as both a TMM route and a management route, the system will prefer the TMM route. This also applies if the only defined management route is a default gateway, the system will prefer the TMM default gateway.
TMM switch routes are routes that the BIG-IP system uses to forward traffic through the TMM switch interfaces instead of through the management interface. Traffic sourced from a TMM (self IP) address will always use the most specific matching TMM route. Traffic sourced from a TMM address will never use a management route. When TMM is not running, the TMM addresses are not available, and all TMM routes are removed. As a result, when TMM is not running, all outbound administrative traffic uses the most specific matching management route.
Starting in BIG-IP 11.3.0, you can configure source addresses from which virtual servers accept traffic. The BIG-IP system uses the destination address, source address, and service port configuration to determine the order of precedence applied to new inbound connections. When a connection matches multiple virtual servers, the BIG-IP system uses an algorithm that places virtual server precedence in the following order:
- Destination address
- Source address
- Service port
Note:
NTP,SNMP,Syslog,Sflow ,remote authentication will always use the management default route unless a TMM interface has a layer2 connectivity to the IP's of those services,or you have a more specific route defined in TMM.
When BIG-IP system using the routes it will select the most specific route to forward the traffic towards the destination.
Example 1 - If the traffic is from the IP address 192.168.0.100 we have the below specific route defined.
net route /Common/192.168.0.100 {
description none
gw 192.168.0.2
mtu 0
network 192.168.0.100/32
partition Common
}
So the traffic will be use the gateway IP 192.168.0.2 to direct the traffic.
Example 2 - If the traffic is from the one of the IP addresses in the network 192.168.0.0. For example let's take IP 192.168.0.102. In this situation the route below will be used.
net route /Common/192.168.0.0 {
description none
gw 192.168.0.1
mtu 0
network 192.168.0.0/16
partition Common
}
So the traffic will be use the gateway IP 192.168.0.1 to direct the traffic.
Example 3 - If the traffic does not match any of the specific routes (neither 192.168.0.100 nor 192.168.0.0) above the BIG-IP system will forward the traffic to the default gateways like the ones you configured below.
default via 172.16.0.1 dev mgmt metric 4096 <-------management route
default via 10.0.0.1 dev TEST-NET-1 <-------TMM route
The traffic will be directed to the TMM route as it has the lower metric compared to the management route.
Commands:-
1.To check routing Table;tmsh show/net route
2.To check the configured static route:tmsh list/net route
3.To check the management route:list/sys management-route
4.To check the management interface IP address:list/sys management-ip.