Proxy-based web application firewalls (WAFs) are an integral component of application protection. In addition to being a requirement for complying with PCI-DSS, WAFs are excellent at protecting against the OWASP Top 10. They’re also a go-to solution for addressing zero-day vulnerabilities either through rapid release of signature updates or, in some cases, the use of programmatic functions to virtually patch applications while a long term solution is being deployed.
The question is, where do you put such protection?
There are options, of course. The data path contains multiple insertion points at which a WAF can be deployed. But that doesn’t mean every insertion point is a good idea. Some are less efficient than others, some introduce unacceptable points of failure, and others introduce architectural debt that incurs heavy interest penalties over time.
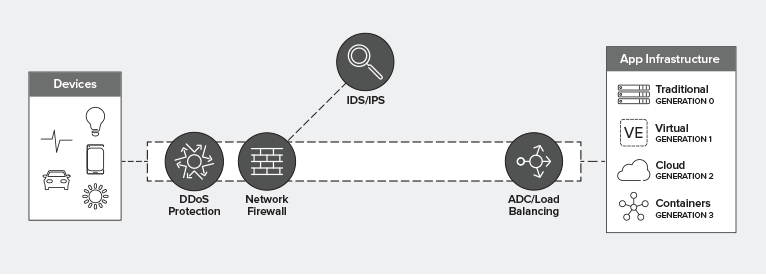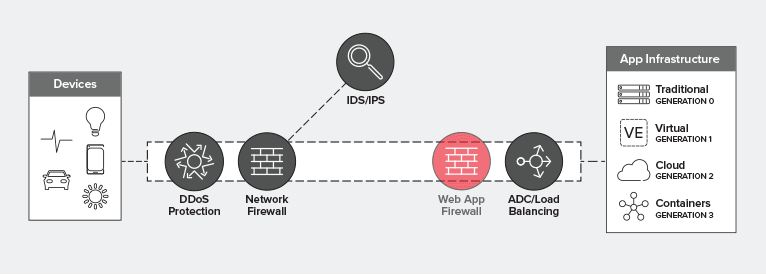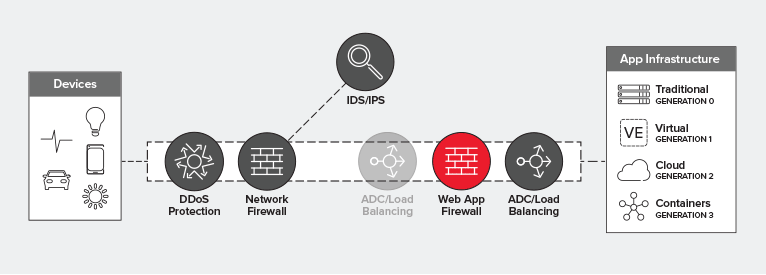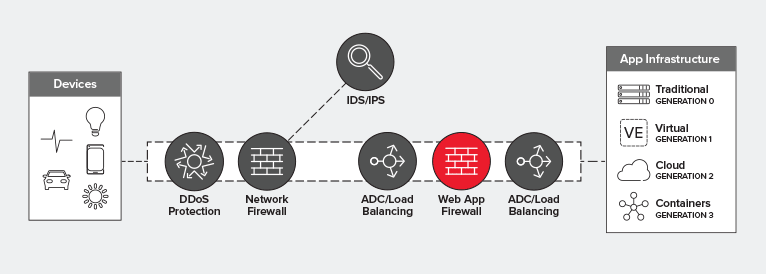
Ideally, you’ll deploy a WAF behind your load balancing tier. This optimizes for utilization, performance, and reliability while providing the protection necessary for all apps – but particularly for those exposed on the Internet.

Utilization
The resource requirements (CPU and the like) involved in making a load balancing decision are minimal. This is generally why a LB is able to simultaneously support millions of users, and WAFs require more utilization – because they're inspecting the entire payload and evaluating it against signatures and policies to determine whether the request is valid and safe.
Modern data center models borrow heavily from cloud and its usage based cost structure. Utilization becomes a key factor in operational costs. Higher utilization leads to additional resource requirements, which consumes budgets. Optimizing for utilization is therefore a sound strategy for constraining costs in both the data center and in public cloud environments.
Reliability
It is common practice to scale WAFs horizontally. That is, you use the LB to scale WAFs. This architectural decision is directly related to utilization. While many WAFs scale well, they can still be overwhelmed by flash traffic or attacks. If the WAF is positioned in front of the LB, you either need another LB tier to separately scale it or you risk impacting performance and availability.
Performance
Performance is a key concern in an application economy. With so many variables and systems interacting with data as it traverses the data path, it can be frustrating to nail down exactly where performance is being bogged down let alone to tune each one without impacting others. As has been noted many times before, as load on a system increases, performance decreases. This is one of the unintended consequences of not optimizing for utilization, and a key reason why seasoned network architects use a 60% utilization threshold on network devices.
Deploying a WAF behind the LB tier eliminates the need for an upstream designated WAF load balancing tier, which removes an entire layer of network from the equation. While the processing time eliminated may not seem like much, those precious microseconds spent managing connections and scaling WAF services and then doing it again to choose a target app instance/server matters. Eliminating this tier by deploying the WAF behind the LB tier gives back precious microseconds that today’s users will not only notice, but appreciate.
Visibility
Visibility is a key requirement for security solutions in the data path. Without the ability to inspect the entire flow – including the payload – much of the security functions of a WAF are rendered moot. After all, most malicious code is found in the payload, not in protocol headers. Positioning a WAF behind the LB tier enables decryption of SSL/TLS before traffic is passed on to the WAF for inspection. This is a more desirable architecture because it is likely the load balancer will need visibility into secured traffic anyway, to determine how to properly route requests.
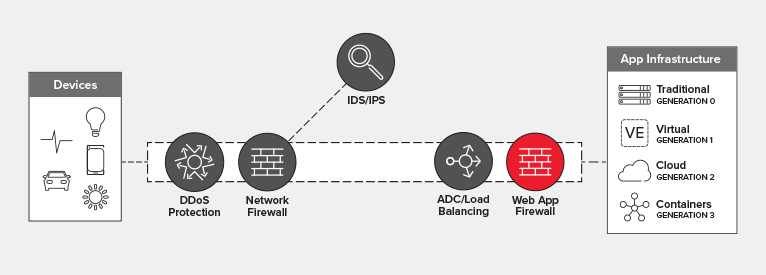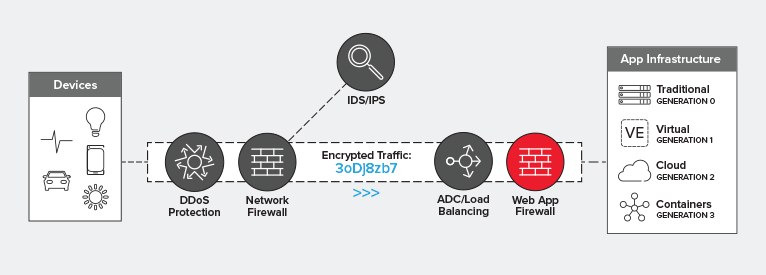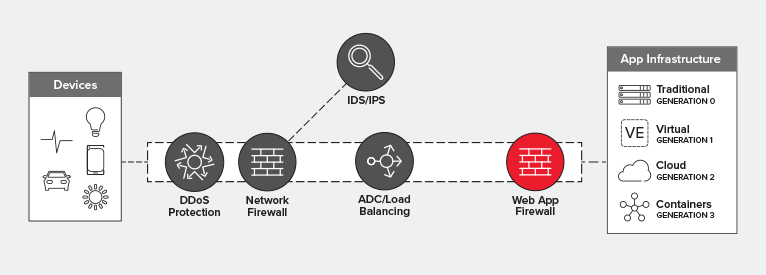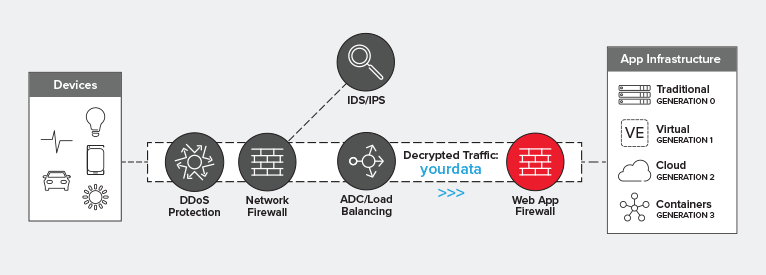
All that said, a WAF fits in the data path pretty much anywhere you want it to. It’s an L7 proxy-based security service deployed as an intermediary in the network path. It could ostensibly sit at the edge of the network, if you wanted it to. But if you want to optimize your architecture for performance, reliability, and utilization at the same time, then your best bet is to position that WAF behind the load balancing tier, closer to the application it is protecting.
Source: F5.com